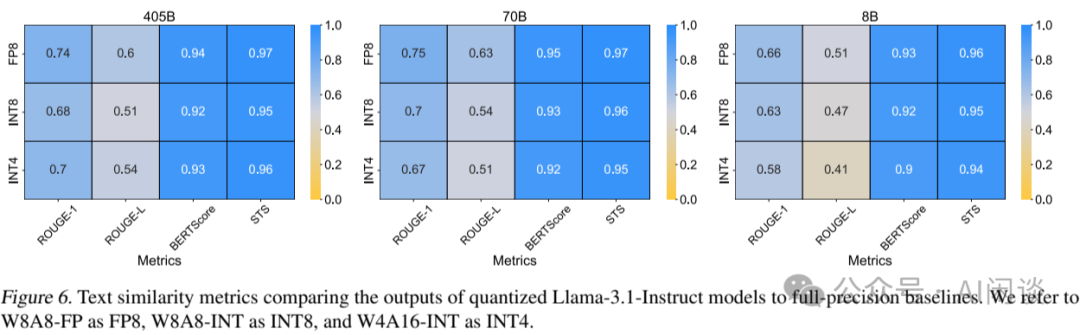
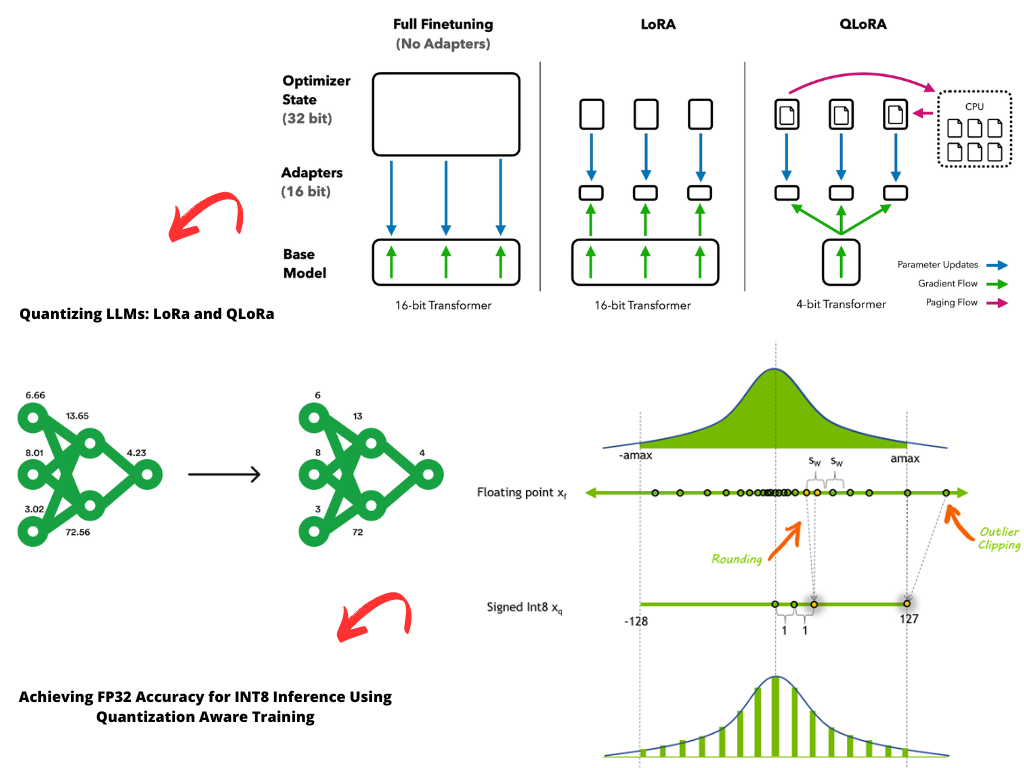
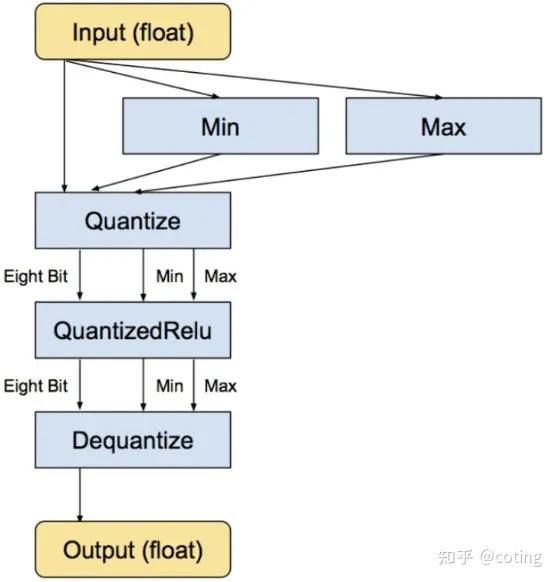
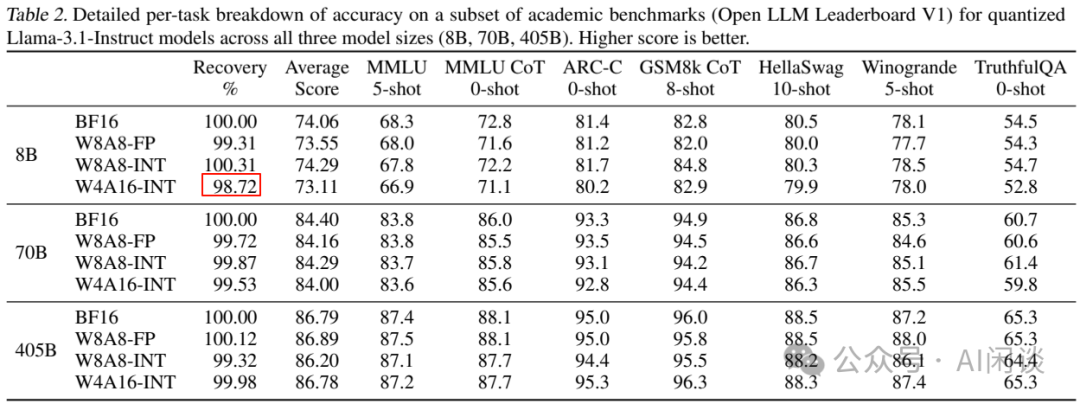
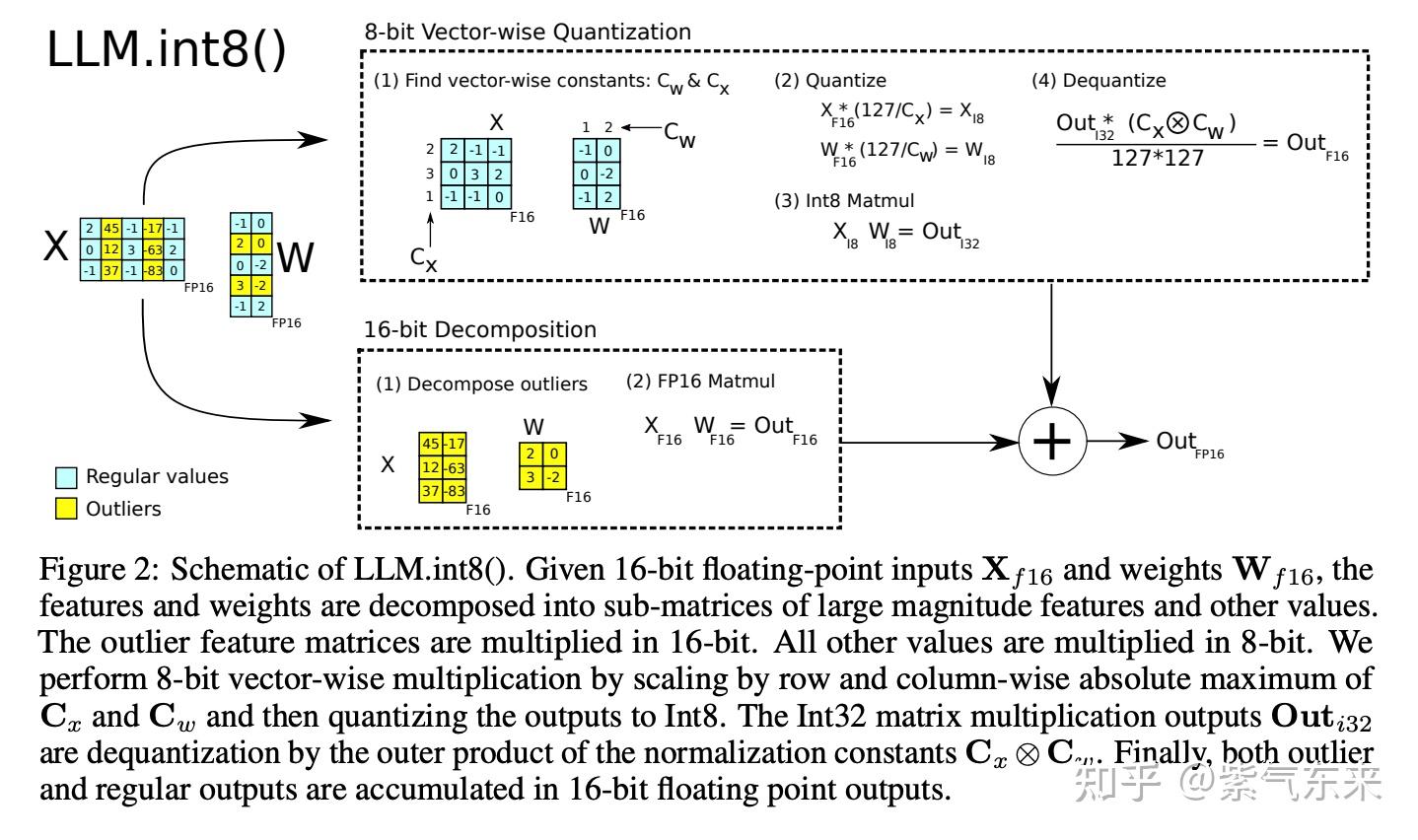
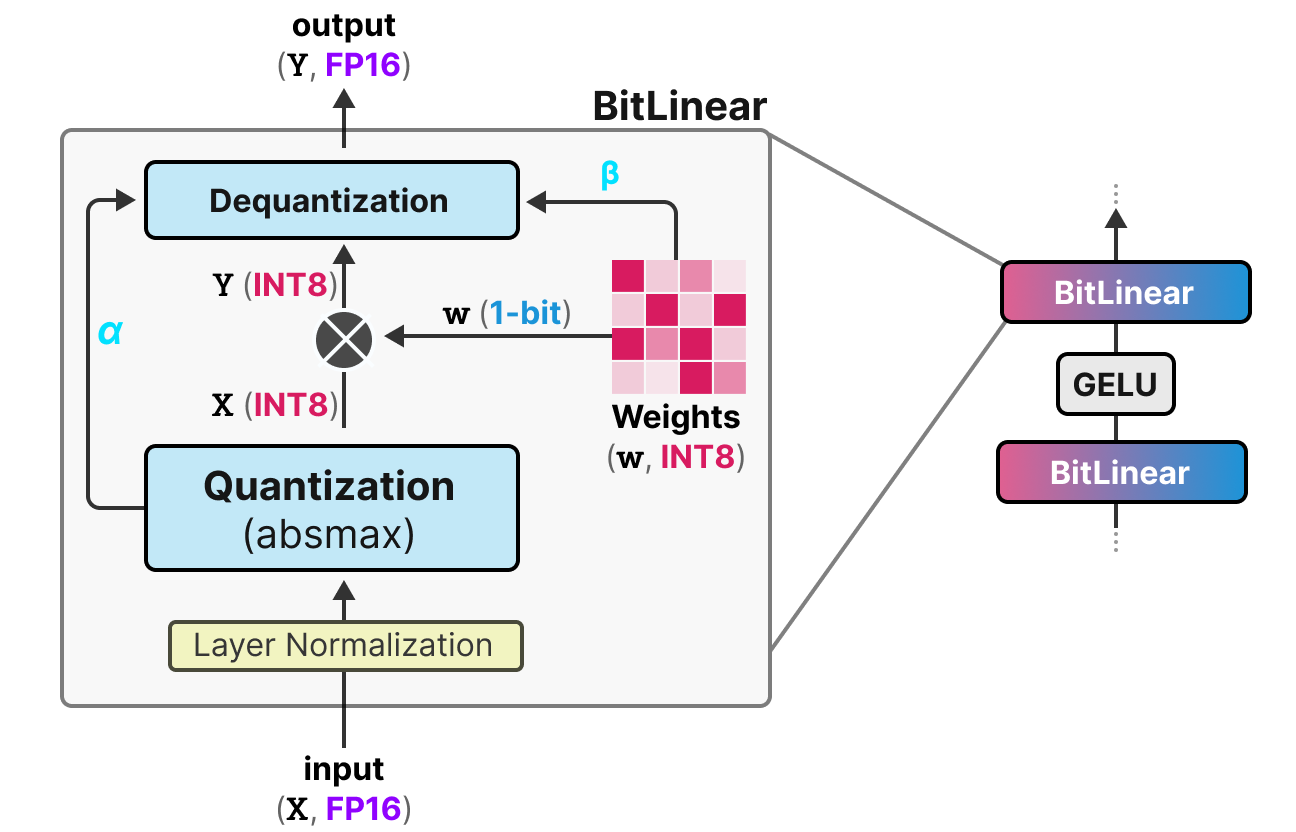
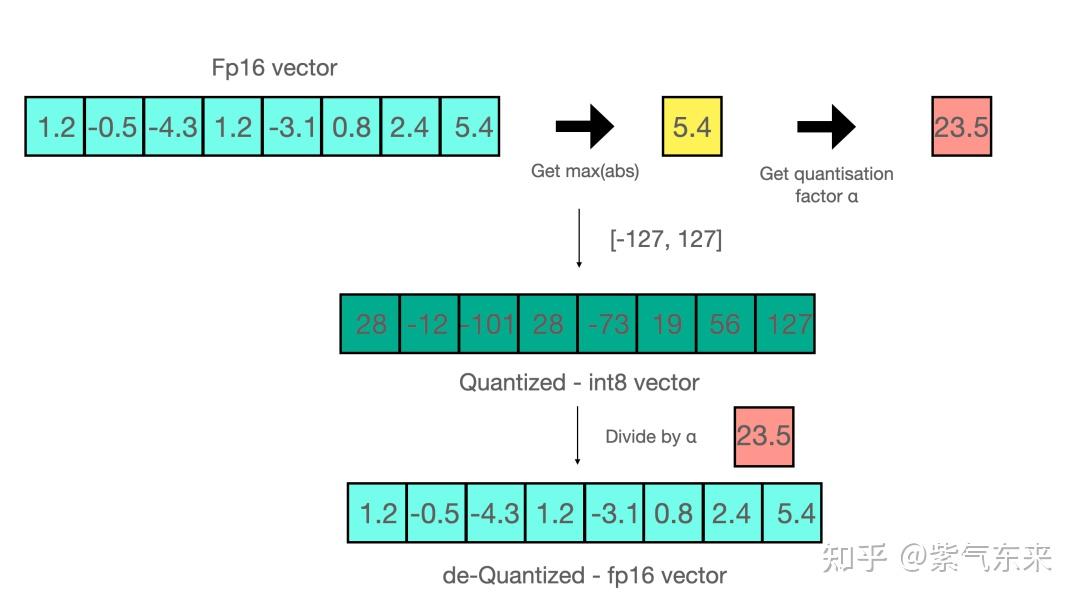
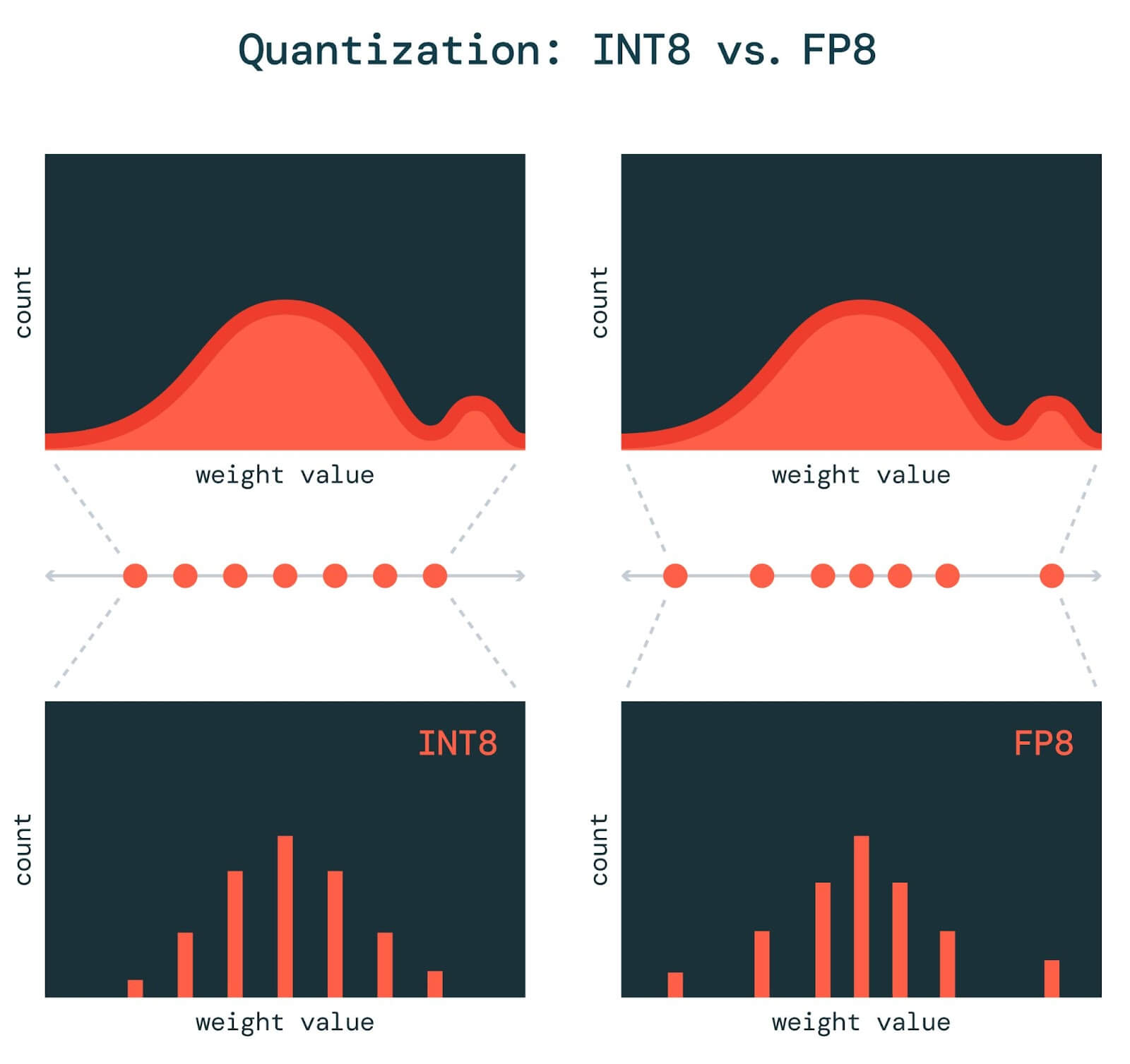
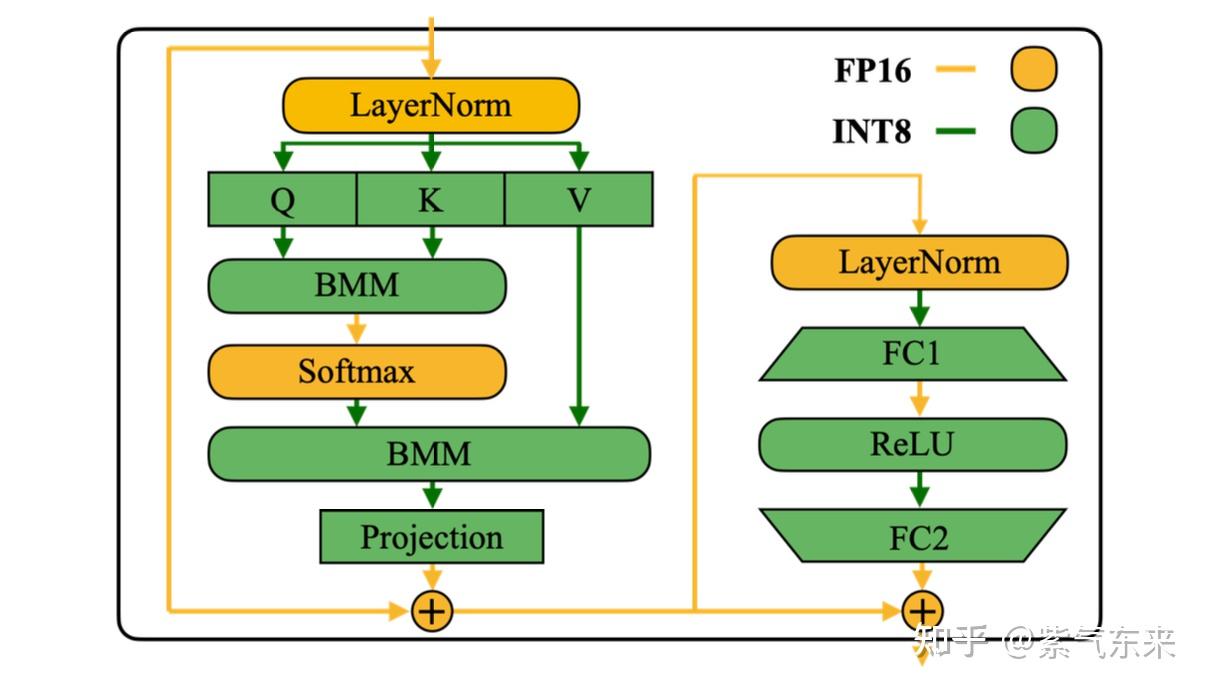
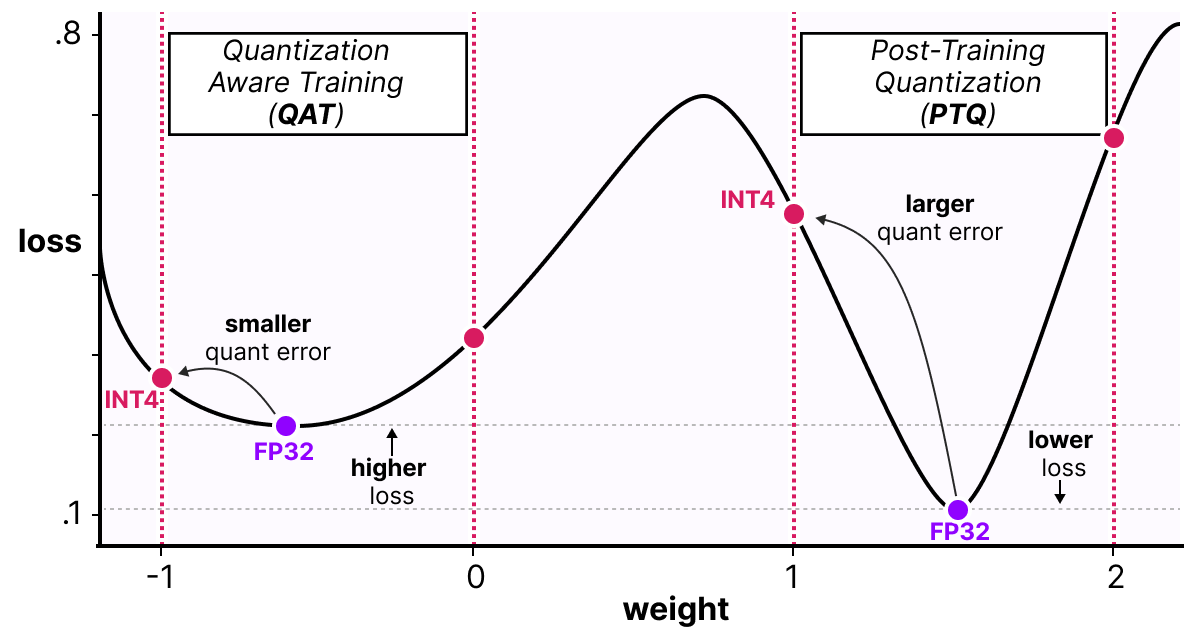
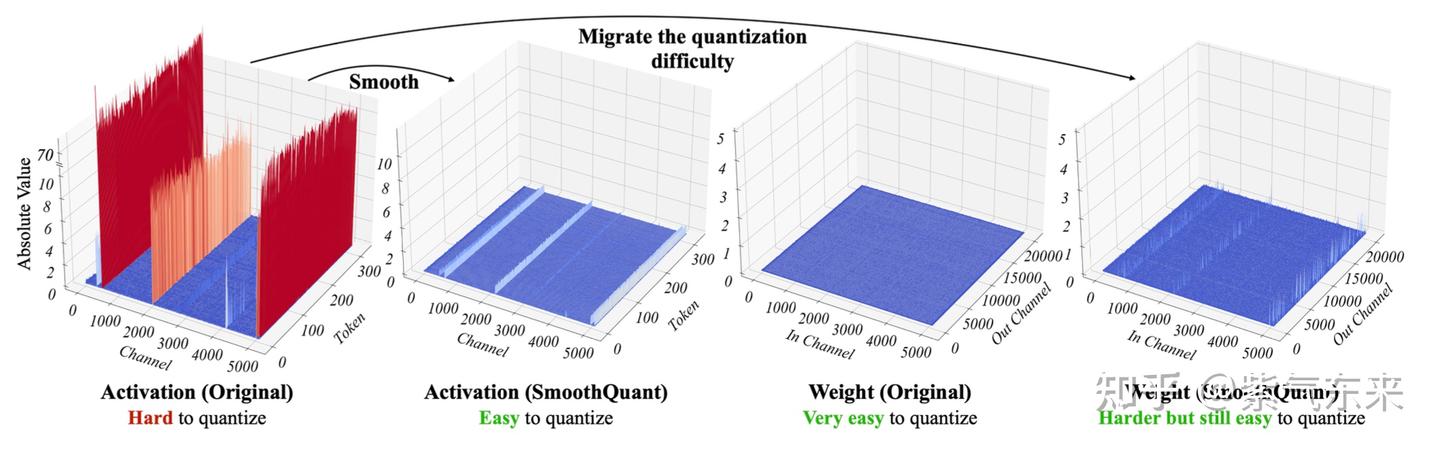
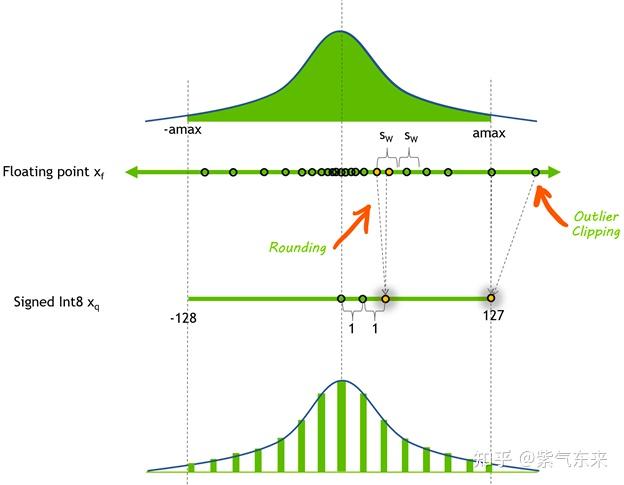
Showing 87 of 87on this page. Filters & sort apply to loaded results; URL updates for sharing.87 of 87 on this page
Day 60/75 LLM Quantization to Convert Float32 to Int8 | LLM Evaluation ...
INT8 and INT4 Quantization ValueError · Issue #35 · moojink/openvla-oft ...
How I optimized an LLM with INT4 quantization and distillation | Shyam ...
Could you upload the INT4 quantization and INT8 quantization model to ...
Improving LLM Inference Latency on CPUs with Model Quantization ...
LLM 推理量化评估:FP8、INT8 与 INT4 的全面对比 - 知乎
4-bit LLM training and Primer on Precision, data types & Quantization
LLM Quantization Explained - YouTube
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
GitHub - intel/neural-compressor: SOTA low-bit LLM quantization (INT8 ...
Top LLM Quantization Methods and Their Impact on Model Quality
INT8, INT4 and Other Integer Types for Quantization
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
面试官:为什么需要量化,为什么 int4 / int8 量化后大模型仍能保持性能? - 知乎
Practical Guide to LLM Quantization Methods - Cast AI
The Ultimate Handbook for LLM Quantization | Towards Data Science
LLM quantization | LLM Inference Handbook
[2301.12017] Understanding INT4 Quantization for Language Models ...
GitHub - r4ghu/llm-quantization: Notes for LLM Quantization
8 LLM Quantization Moves for 60% Cheaper Inference | by Hash Block ...
Data Types in LLM Quantization
Exploring Model Quantization for LLMs | by Snehal | Medium
LLM 量化技术小结 - 知乎
A Hands-On Walkthrough on Model Quantization - Medoid AI
[2303.17951] FP8 versus INT8 for efficient deep learning inference
LLM Quantization: Making models faster and smaller | MatterAI Blog
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
Quantization Methods for 100X Speedup in Large Language Model Inference
Quark Quantized INT8 Models - a amd Collection
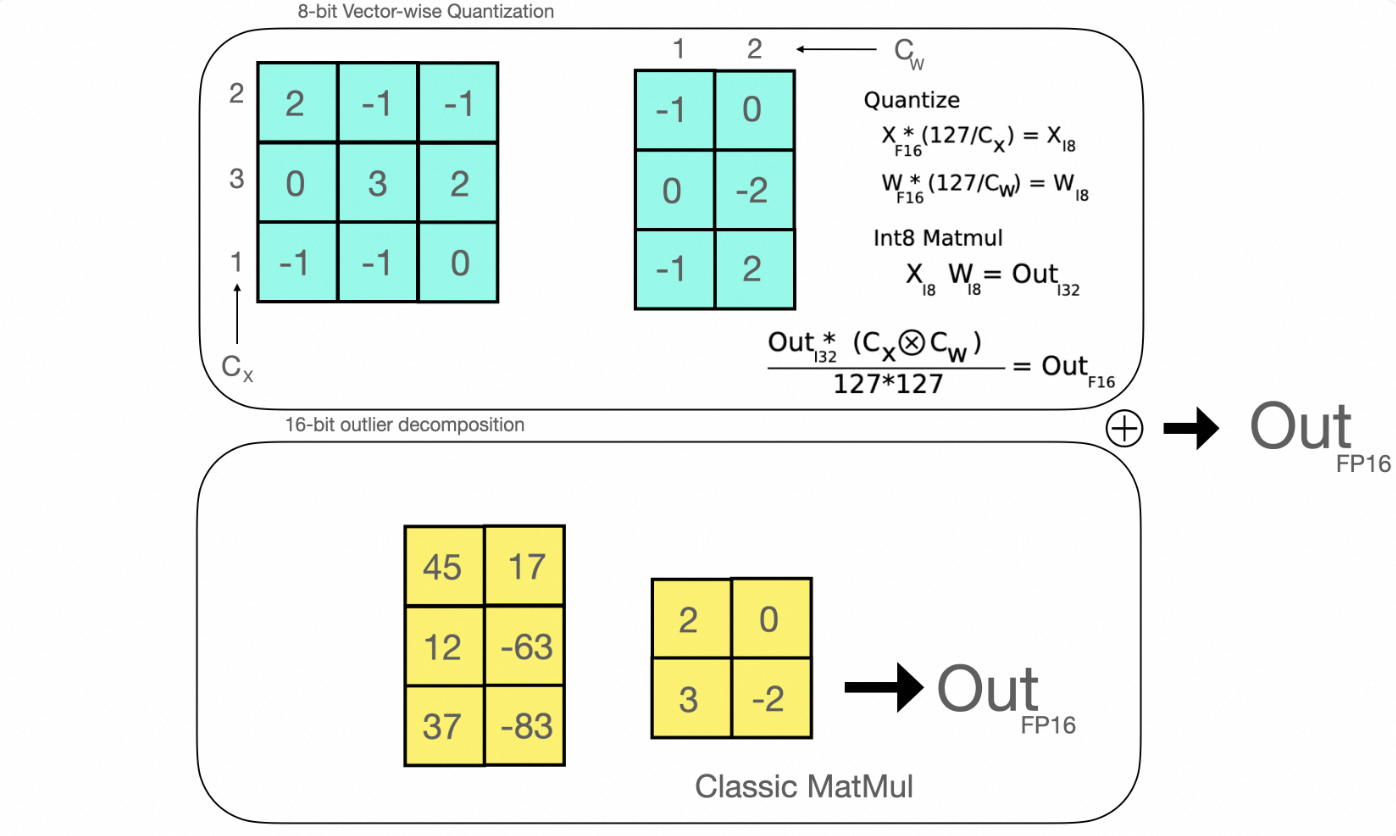
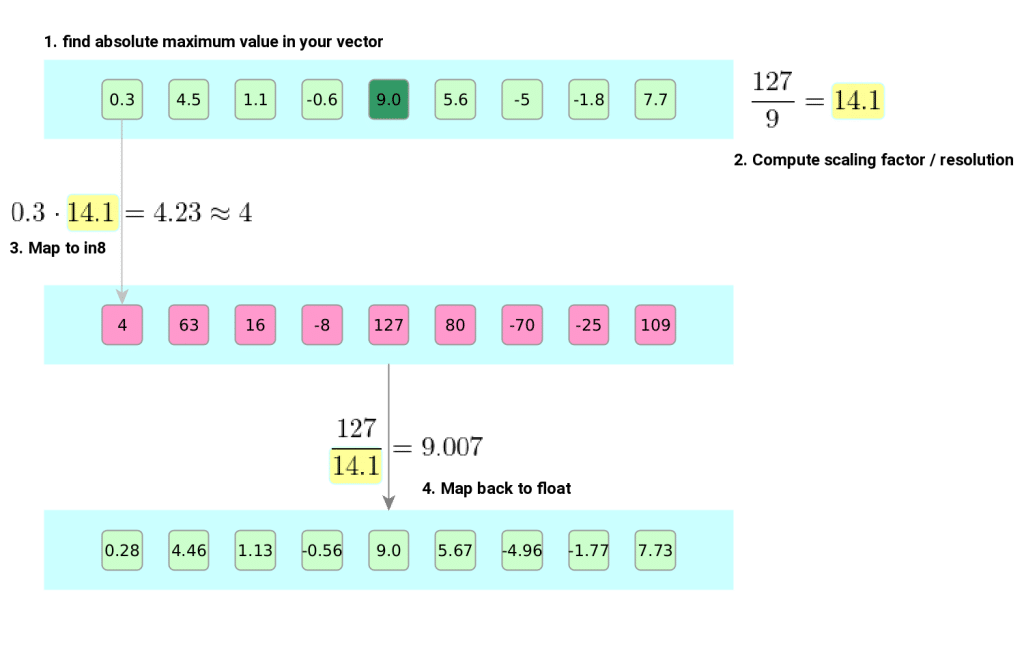
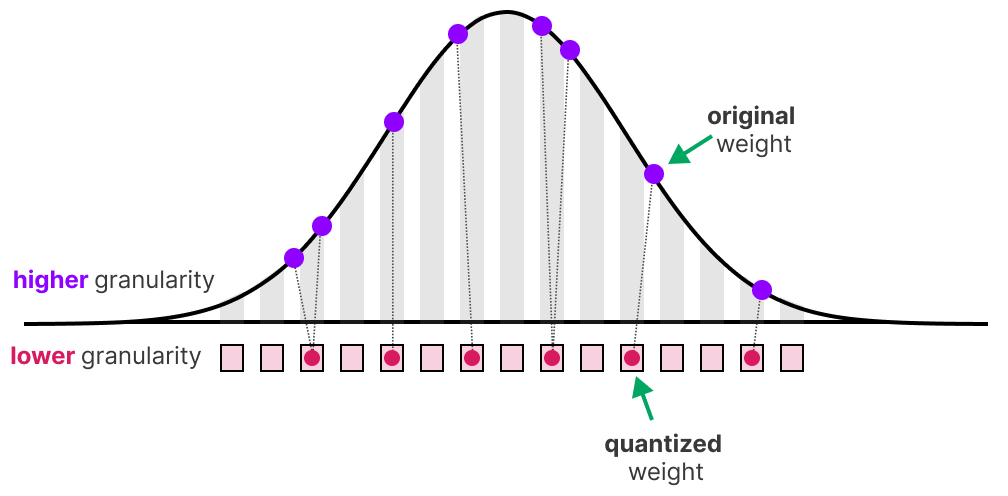
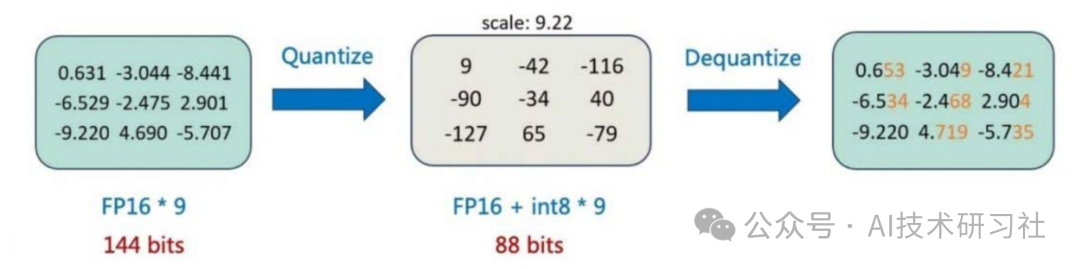
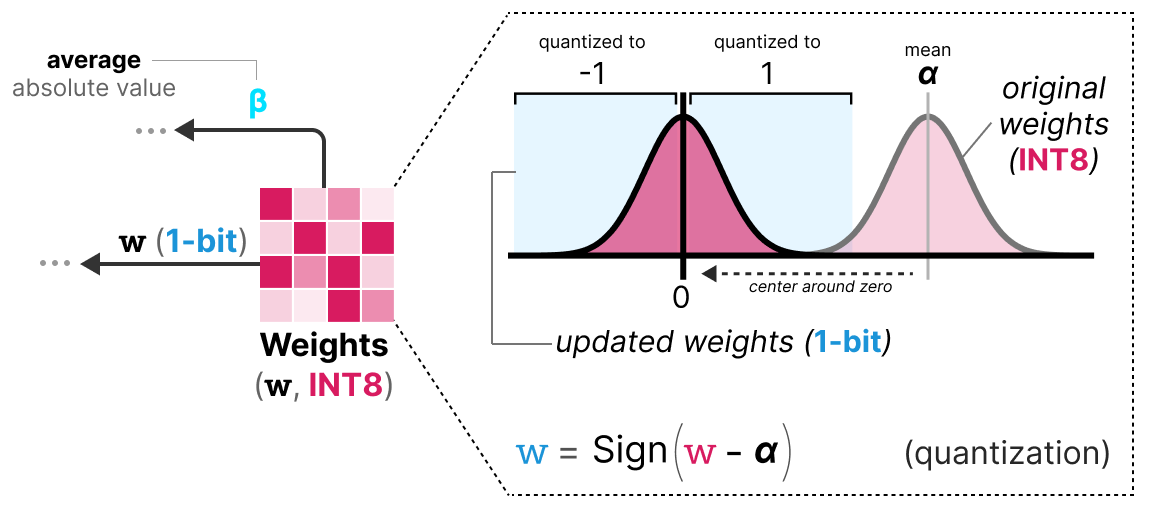
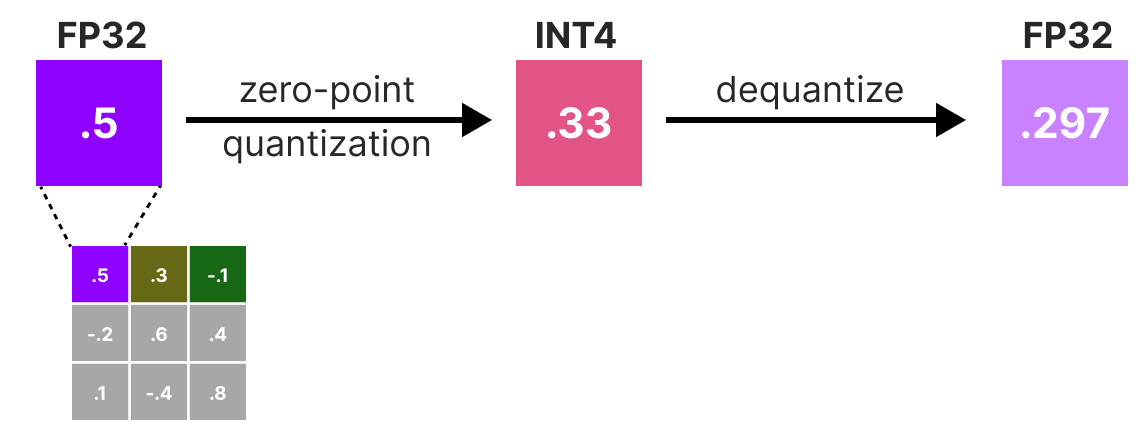
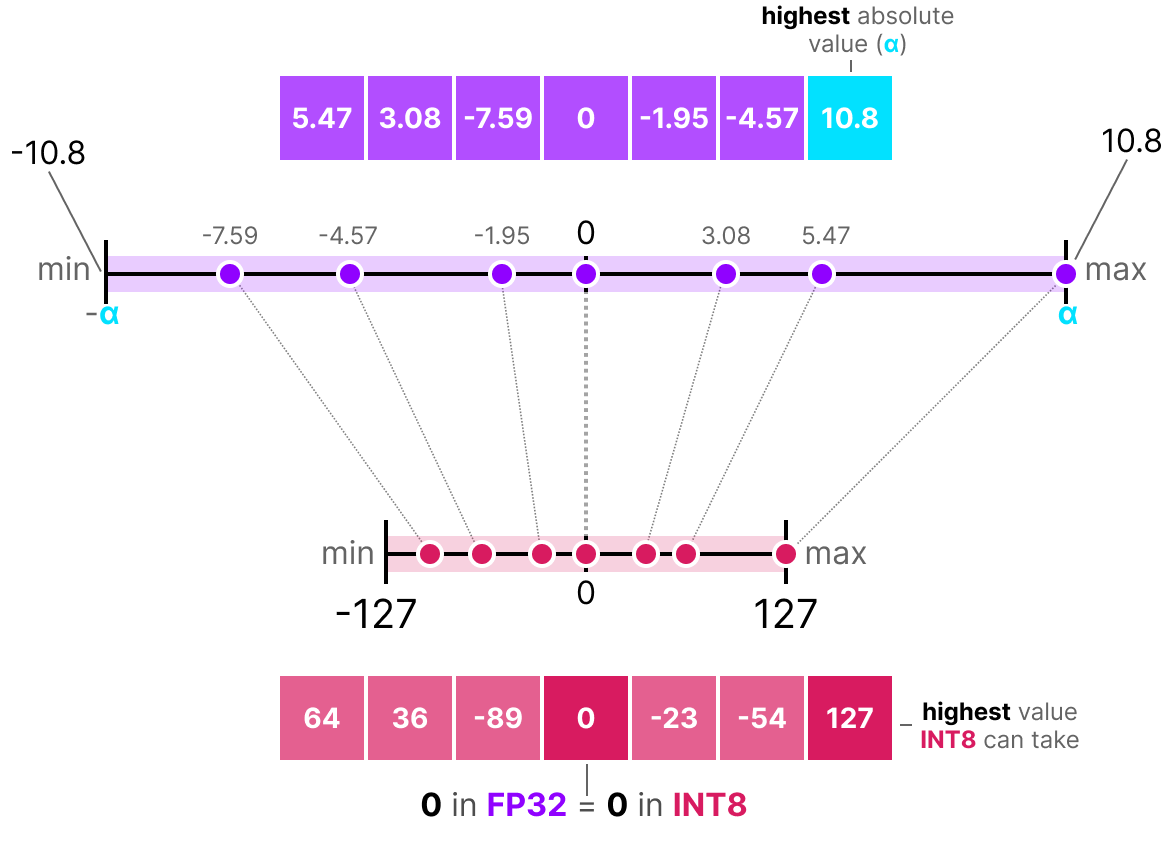
A Visual Guide to Quantization - by Maarten Grootendorst
LLM Quantization-Build and Optimize AI Models Efficiently
Introduction to Weight Quantization | Towards Data Science
LLM 大模型学习必知必会系列(六):量化技术解析_牛客网
[Ep3] LLM Quantization: LLM.int8(), QLoRA, GPTQ, ... - YouTube
Cost Optimization in LLM Hosting | AI Tutorial | Next Electronics
Local Large Language Models | Int8
A Guide to Quantization in LLMs | Symbl.ai
Introduction to Weight Quantization - Origins AI
Understanding LLM.int8() Quantization — Picovoice
A Visual Guide to Quantization - Maarten Grootendorst
Quark Quantized INT4 ONNX Models - a amd Collection
LLM Compressor is here: Faster inference with vLLM | Red Hat Developer
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
MSU AI Club
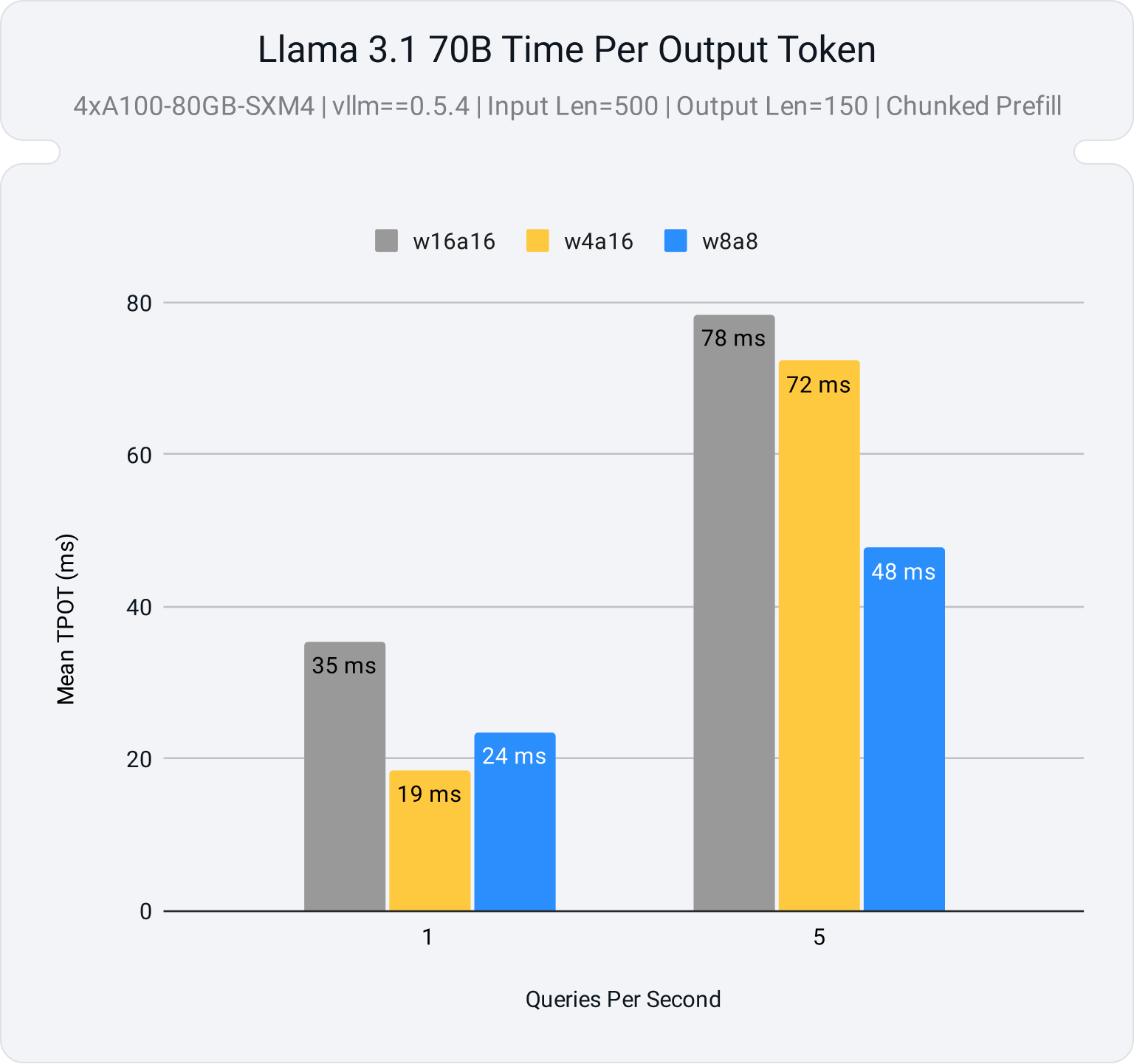
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
【科普】大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析 - 墨天轮
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度_风闻
Quantization-Aware Training for Large Language Models with PyTorch ...
Analytics Vidhya | Data Science Community | 🚀 Day 31 of Mastering LLMs ...
[LLM量化] LLM.int8(), GPTQ, SmoothQuant, AWQ, SqueezeLLM, ATOM, OmniQuant ...
[핵심][22.08]LLM.int8()
模型量化(int8)系统知识导读_int4量化-CSDN博客
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale论文解读 ...